
KahaPilot: Private documentation layer powering AI assistants and coding agents.
Designed & Built · 2025 – Present
A documentation-grounded AI coding assistant for Fenergo (Fen-X) integration work, built end-to-end as an internal tool for Kaha Management. LLMs hallucinate on specialised vendor APIs because their training data rarely covers them. KahaPilot fixes this by hosting a private semantic search index of developer documentation, curated internal Stack Overflow knowledge, integration patterns and templates, and more, locally on each developer's machine, and exposes it to Claude Code and Claude Desktop over the Model Context Protocol.
This system is a component in functional knowledge uses as well as agentic coding systems.
What it does
When a developer asks Claude to write Fenergo code, Claude searches the local index first and grounds every response in authoritative documentation. The corpus covers ~2,900 Developer Hub pages, hundreds of Swagger / OpenAPI specifications, and ~5,000 quality-curated answers from the internal Stack Overflow for Teams instance. Retrieval runs entirely on the developer's laptop, with no external API calls and no data leaving the organisation.
Functional consultants use it the same way through Claude Desktop. When they need a specific piece of information, Claude answers from the grounded corpus and surfaces direct links to the relevant sources for verification and further reading.
Agentic research pipeline
For broad integration requirements, the system runs an internal multi-stage pipeline rather than a single search. A rule-based decomposition step tokenises the requirement against a corpus-derived vocabulary table covering Fenergo entities, API clusters, and subsystems, then emits 4-6 targeted sub-queries. Those queries run in parallel, results are fused via Reciprocal Rank Fusion, and chunks are re-ranked by cosine similarity against the original requirement embedding. Narrow lookups take a fast path; complex requirements trigger a deeper retrieval round when coverage is low.
The pipeline then synthesises a structured implementation plan with cited source URLs using MCP Sampling, which routes the synthesis request through whichever model the developer already has open in Claude Desktop or Code. There is no Anthropic API key in the repo and no second LLM client. The system uses the AI already in the room.
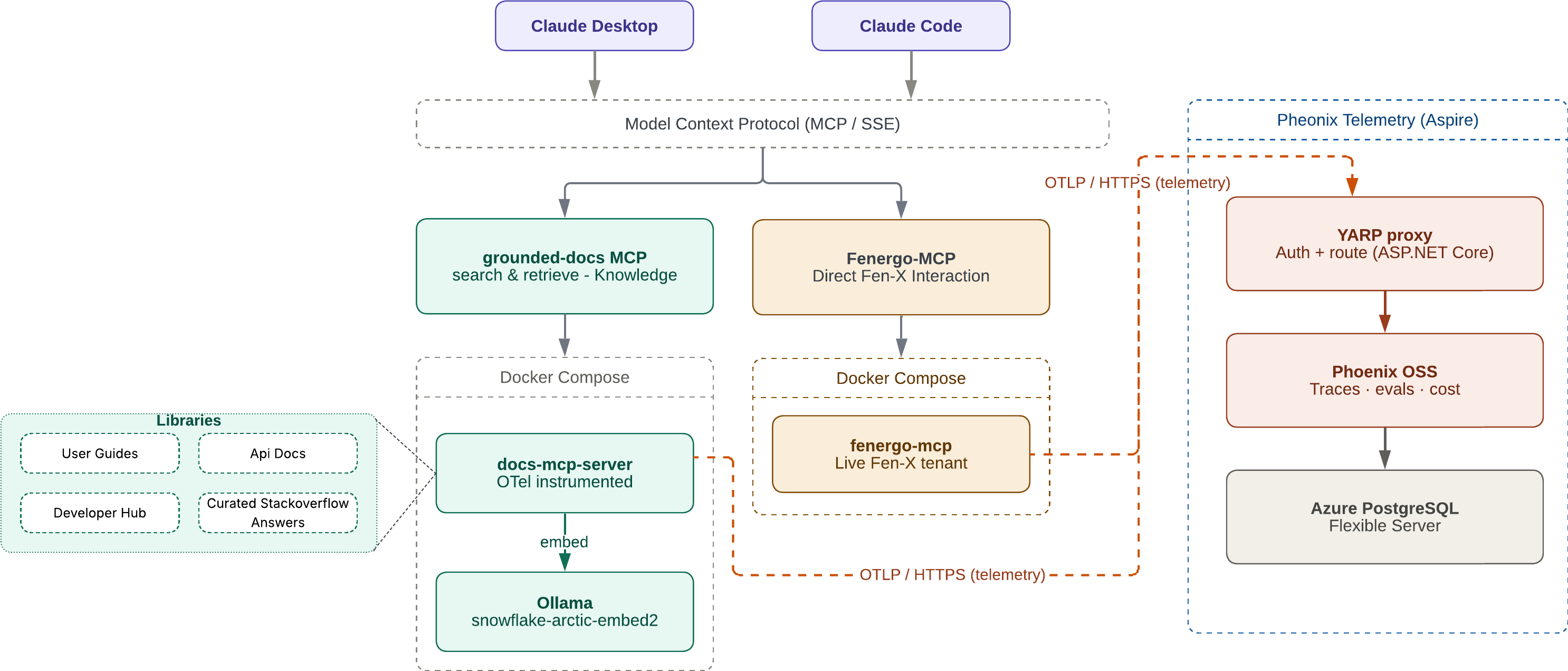
Architecture
A small Node.js MCP wrapper fronts grounded-docs, an extended build of the open-source arabold/docs-mcp-server. The wrapper re-exposes its tools with Fenergo-scoped descriptions, enriches results with canonical source URLs, and emits OpenInference TOOL spans asynchronously so telemetry never blocks retrieval. The whole stack ships as a single Docker Compose project that a developer brings up with one command.
Indexing & distribution
Documentation is chunked along Markdown structure so each chunk holds one self-contained idea: a single endpoint, a concept, a Q&A pair. Chunks are embedded locally with snowflake-arctic-embed2 and persisted into a SQLite vector store. The pre-indexed store ships as a compressed archive in Git LFS, and a scheduled job rebuilds it weekly. Developer machines simply git pull to refresh, with first grounded query under five minutes from a clean clone.
Telemetry & observability
A companion Phoenix OSS deployment captures every MCP tool call, giving engineering leads visibility into which docs are retrieved, retrieval latency, token consumption, and per-user activity. Phoenix is deployed to Azure Container Apps via a small Aspire project and surfaced back into Claude Desktop as an MCP server, so leads can query traces in natural language.